Analyzing ADCP Data with MHKiT
The following example illustrates a straightforward workflow for analyzing Acoustic Doppler Current Profiler (ADCP) data utilizing MHKiT. MHKiT has integrated the DOLfYN codebase as a module to facilitate ADCP and Acoustic Doppler Velocimetry (ADV) data processing.
Here is a standard workflow for ADCP data analysis:
Import Data
Review, QC, and Prepare the Raw Data:
Calculate or verify the correctness of depth bin locations
Discard data recorded above the water surface or below the seafloor
Assess the quality of velocity, beam amplitude, and/or beam correlation data
Rotate Data Coordinate System
Data Averaging:
If not already executed within the instrument, average the data into time bins of a predetermined duration, typically between 5 and 10 minutes
Speed and Direction
Plotting
Saving and Loading DOLfYN datasets
Turbulence Statistics
Turbulence Intensity (TI)
Power Spectral Densities
Instrument Noise
TKE Dissipation Rate
Noise-corrected TI
Reynolds stresses
TKE Production
TKE Balance
Begin your analysis by importing the requisite tools:
[33]:
from mhkit import dolfyn
from mhkit.dolfyn.adp import api
1. Importing Raw Instrument Data
One of DOLfYN’s key features is its ability to directly import raw data from an Acoustic Doppler Current Profiler (ADCP) right after it has been transferred. In this instance, we are using a Nortek Signature1000 ADCP, with the data stored in files with an ‘.ad2cp’ extension. This specific dataset represents several hours of velocity data, captured at 1 Hz by an ADCP mounted on a bottom lander within a tidal inlet. The list of instruments compatible with DOLfYN can be found in the MHKiT DOLfYN documentation.
We’ll start by importing the raw data file downloaded from the instrument. The read function processes the raw file and converts the information into an xarray Dataset. This Dataset includes several groups of variables:
Velocity: Recorded in the coordinate system saved by the instrument (beam, XYZ, ENU)
Beam Data: Includes amplitude and correlation data
Instrumental & Environmental Measurements: Captures the instrument’s bearing and environmental conditions
Orientation Matrices: Used by DOLfYN for rotating through different coordinate frames.
[34]:
ds = dolfyn.read("data/dolfyn/Sig1000_tidal.ad2cp")
Reading file data/dolfyn/Sig1000_tidal.ad2cp ...
There are two ways to see what’s in a Dataset. The first is to simply type the dataset’s name to see the standard xarray output. To access a particular variable in a dataset, use dict-style (ds['vel']) or attribute-style syntax (ds.vel). See the xarray docs for more details on how to use the xarray format.
[35]:
# print the dataset
ds
[35]:
<xarray.Dataset> Size: 83MB
Dimensions: (time: 55000, time_b5: 55000, range: 28, range_b5: 28,
beam: 4, dir: 4, dirIMU: 3, earth: 3, inst: 3, q: 4,
x1: 4, x2: 4)
Coordinates:
* time (time) datetime64[ns] 440kB 2020-08-15T00:20:00.5009...
* time_b5 (time_b5) datetime64[ns] 440kB 2020-08-15T00:20:00.4...
* range (range) float64 224B 0.6 1.1 1.6 2.1 ... 13.1 13.6 14.1
* range_b5 (range_b5) float64 224B 0.6 1.1 1.6 ... 13.1 13.6 14.1
* beam (beam) int32 16B 1 2 3 4
* dir (dir) <U2 32B 'E' 'N' 'U1' 'U2'
* dirIMU (dirIMU) <U1 12B 'E' 'N' 'U'
* earth (earth) <U1 12B 'E' 'N' 'U'
* inst (inst) <U1 12B 'X' 'Y' 'Z'
* q (q) <U1 16B 'w' 'x' 'y' 'z'
* x1 (x1) int32 16B 1 2 3 4
* x2 (x2) int32 16B 1 2 3 4
Data variables: (12/38)
c_sound (time) float32 220kB 1.502e+03 1.502e+03 ... 1.498e+03
temp (time) float32 220kB 14.55 14.55 14.55 ... 13.47 13.47
pressure (time) float32 220kB 9.713 9.718 9.718 ... 9.594 9.596
mag (dirIMU, time) float32 660kB 72.5 72.7 ... -195.7
accel (dirIMU, time) float32 660kB -0.00479 ... 9.729
batt (time) float32 220kB 16.6 16.6 16.6 ... 16.4 16.4 15.2
... ...
telemetry_data (time) uint8 55kB 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0
boost_running (time) uint8 55kB 0 0 0 0 0 0 0 0 1 ... 1 0 0 0 0 0 0 1
heading (time) float32 220kB -12.52 -12.51 ... -12.52 -12.5
pitch (time) float32 220kB -0.065 -0.06 -0.06 ... -0.05 -0.05
roll (time) float32 220kB -7.425 -7.42 -7.42 ... -6.45 -6.45
beam2inst_orientmat (x1, x2) float32 64B 1.183 0.0 -1.183 ... 0.0 0.5518
Attributes: (12/34)
filehead_config: {"CLOCKSTR": {"TIME": "\"2020-08-13 13:56:21\""}, ...
inst_model: Signature1000
inst_make: Nortek
inst_type: ADCP
burst_config: {"press_valid": true, "temp_valid": true, "compass...
n_cells: 28
... ...
proc_idle_less_12pct: 0
rotate_vars: ['vel', 'accel', 'accel_b5', 'angrt', 'angrt_b5', ...
coord_sys: earth
fs: 1
has_imu: 1
beam_angle: 25A second way provided to look at data is through the DOLfYN view. This view has several convenience methods, shortcuts, and functions built-in. It includes an alternate – and somewhat more informative/compact – description of the data object when in interactive mode. This can be accessed using
[36]:
ds_dolfyn = ds.velds
ds_dolfyn
[36]:
<ADCP data object>: Nortek Signature1000
. 15.28 hours (started: Aug 15, 2020 00:20)
. earth-frame
. (55000 pings @ 1Hz)
Variables:
- time ('time',)
- time_b5 ('time_b5',)
- vel ('dir', 'range', 'time')
- vel_b5 ('range_b5', 'time_b5')
- range ('range',)
- orientmat ('earth', 'inst', 'time')
- heading ('time',)
- pitch ('time',)
- roll ('time',)
- temp ('time',)
- pressure ('time',)
- amp ('beam', 'range', 'time')
- amp_b5 ('range_b5', 'time_b5')
- corr ('beam', 'range', 'time')
- corr_b5 ('range_b5', 'time_b5')
- accel ('dirIMU', 'time')
- angrt ('dirIMU', 'time')
- mag ('dirIMU', 'time')
... and others (see `<obj>.variables`)
2. Initial Steps for Data Quality Control (QC)
2.1: Set the Deployment Height
When using Nortek instruments, the deployment software does not factor in the deployment height. The deployment height represents the position of the Acoustic Doppler Current Profiler (ADCP) within the water column.
In this context, the center of the first depth bin is situated at a distance that is the sum of three elements: 1. Deployment height (the ADCP’s position in the water column) 2. Blanking distance (the minimum distance from the ADCP to the first measurement point) 3. Cell size (the vertical distance of each measurement bin in the water column)
To ensure accurate readings, it is critical to calibrate the ‘range’ coordinate to make ‘0’ correspond to either the seafloor or sea surface. This calibration can be achieved using the set_range_offset function.
For those using a Teledyne RDI ADCP, the TRDI deployment software will prompt you to specify the deployment height/depth during setup in order to automatically calculate water depth. If there’s a need for calibration post-deployment, the set_range_offset function can be utilized in the same way as described above to override the initially specified value.
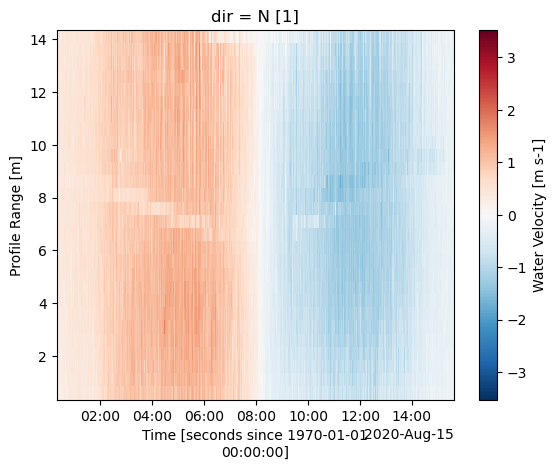
[37]:
ds["vel"][1].plot()
[37]:
<matplotlib.collections.QuadMesh at 0x112d98e1190>
[38]:
# The ADCP transducers were measured to be 0.6 m from the feet of the lander
api.clean.set_range_offset(ds, 0.6)
So, the center of bin 1 is located at 1.2 m:
[39]:
ds.range
[39]:
<xarray.DataArray 'range' (range: 28)> Size: 224B
array([ 1.2, 1.7, 2.2, 2.7, 3.2, 3.7, 4.2, 4.7, 5.2, 5.7, 6.2, 6.7,
7.2, 7.7, 8.2, 8.7, 9.2, 9.7, 10.2, 10.7, 11.2, 11.7, 12.2, 12.7,
13.2, 13.7, 14.2, 14.7])
Coordinates:
* range (range) float64 224B 1.2 1.7 2.2 2.7 3.2 ... 13.2 13.7 14.2 14.7
Attributes:
coverage_content_type: coordinate
units: m
long_name: Profile Range
description: Distance to the center of each depth bin2.2. Discard Data Above Surface Level and Surface Interference
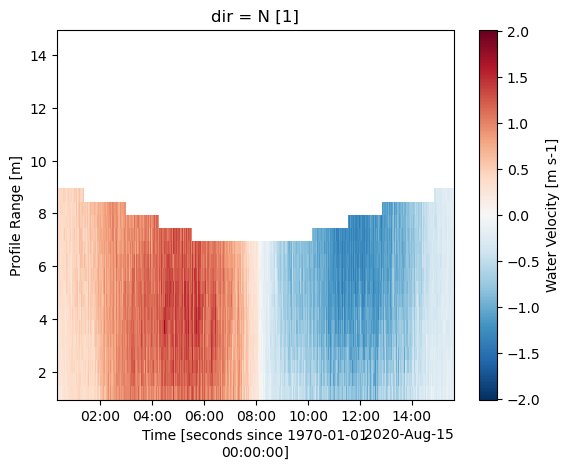
To reduce computational load, we can exclude all data at or above the water surface level, including that affected by surface interference. Since the instrument was oriented upwards, we can utilize the pressure sensor data along with the function water_depth_from_pressure to find the water depth. However, this approach necessitates that the pressure sensor was calibrated or ‘zeroed’ prior to deployment. If the instrument is facing downwards or doesn’t include pressure data, the function
water_depth_from_amplitude can be used to detect the seabed or water surface.
It’s important to note that Acoustic Doppler Current Profilers (ADCPs) do not measure water salinity, so you’ll need to supply this information to the function. If water_depth_from_pressure is called after set_range_offset, “depth” represents the distance from the water surface to the seafloor. Otherwise, it indicates the distance to the ADCP pressure sensor.
After determining the “depth”, you can use the remove_surface_interference function to discard data in depth bins at or above the actual water surface. Be aware that this function will generate a new dataset.
[40]:
api.clean.water_depth_from_pressure(ds, salinity=31)
ds = api.clean.remove_surface_interference(ds)
[41]:
ds["vel"][1].plot()
[41]:
<matplotlib.collections.QuadMesh at 0x112d90785d0>
2.3: Apply an Acoustic Signal Correlation Filter
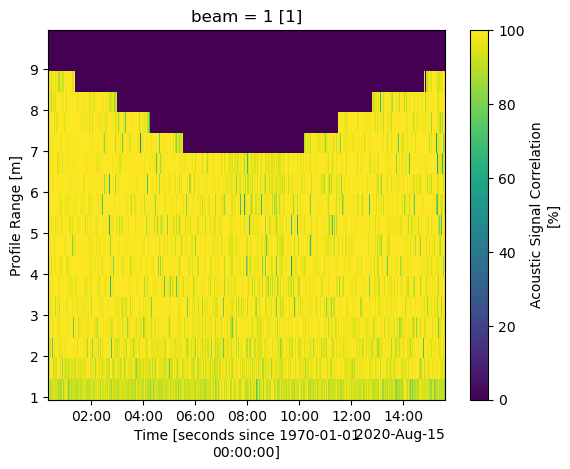
After removing data from bins at or above the water surface, we typically apply a filter based on acoustic signal correlation to the ADCP data. This helps to eliminate erroneous velocity data points, which can be caused by factors such as bubbles, kelp, fish, etc., moving through one or multiple beams.
You can quickly inspect the data to determine an appropriate correlation value by using the built-in plotting feature of xarray. In the following example, we use xarray’s slicing capabilities to display data from beam 1 within a range of 0 to 10 m from the ADCP.
It’s important to note that not all ADCPs provide acoustic signal correlation data, which serves as a quantitative measure of signal quality. Older ADCPs may not offer this feature, in which case you can skip this step when using such instruments.
[42]:
%matplotlib inline
ds["corr"].sel(beam=1, range=slice(0, 10)).plot()
[42]:
<matplotlib.collections.QuadMesh at 0x112d975e410>
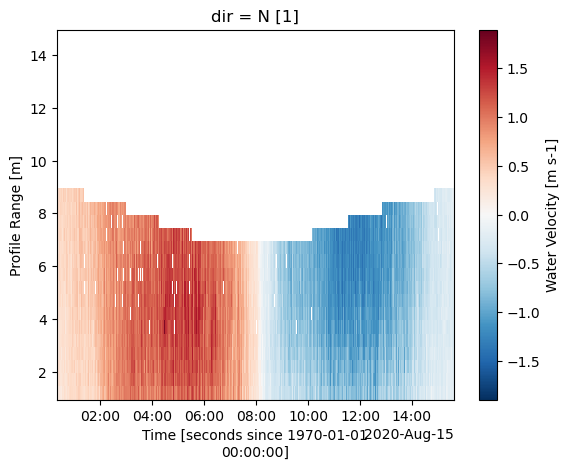
It’s beneficial to also review data from the other beams. A significant portion of this data is of high quality. To avoid discarding valuable data with lower correlations, which could be due to natural variations, we can use the correlation_filter. This function assigns a value of NaN (not a number) to velocity values corresponding to correlations below 50%.
However, it’s important to note that the correlation threshold is dependent on the specifics of the deployment environment and the instrument used. It’s not unusual to set a threshold as low as 30%, or even to forgo the use of this function entirely.
[43]:
ds = api.clean.correlation_filter(ds, thresh=50)
[44]:
ds["vel"][1].plot()
[44]:
<matplotlib.collections.QuadMesh at 0x112d83afe10>
2.4 Rotate Data Coordinate System
After cleaning the data, the next step is to rotate the velocity data into accurate East, North, Up (ENU) coordinates.
ADCPs utilize an internal compass or magnetometer to determine magnetic ENU directions. You can use the set_declination function to adjust the velocity data according to the magnetic declination specific to your geographical coordinates. This declination can be looked up online for specific coordinates.
Instruments save vector data in the coordinate system defined in the deployment configuration file. To make this data meaningful, it must be transformed through various coordinate systems (“beam”<->”inst”<->”earth”<->”principal”). This transformation is accomplished using the rotate2 function. If the “earth” (ENU) coordinate system is specified, DOLfYN will automatically rotate the dataset through the required coordinate systems to reach the “earth” coordinates. Setting inplace to true
will modify the input dataset directly, meaning it will not create a new dataset.
In this case, since the ADCP data is already in the “earth” coordinate system, the rotate2 function will return the input dataset without modifications. The set_declination function will work no matter the coordinate system.
[45]:
dolfyn.set_declination(ds, 15.8, inplace=True) # 15.8 deg East
dolfyn.rotate2(ds, "earth", inplace=True)
Data is already in the earth coordinate system
To rotate into the principal frame of reference (streamwise, cross-stream, vertical), if desired, we must first calculate the depth-averaged principal flow heading and add it to the dataset attributes. Then the dataset can be rotated using the same rotate2 function. We use inplace=False because we do not want to alter the input dataset here.
[46]:
ds.attrs["principal_heading"] = dolfyn.calc_principal_heading(ds["vel"].mean("range"))
ds = dolfyn.rotate2(ds, "principal", inplace=False)
3. Average the Data
As this deployment was configured in “burst mode”, a standard step in the analysis process is to average the velocity data into time bins.
However, if the instrument was set up in an “averaging mode” (where a specific profile and/or average interval was set, for instance, averaging 5 minutes of data every 30 minutes), this step would have been performed within the ADCP during deployment and can thus be skipped.
To average the data into time bins (also known as ensembles), you should first initialize the binning tool ADPBinner. The parameter “n_bin” represents the number of data points in each ensemble. In this case, we’re dealing with 300 seconds’ worth of data. The “fs” parameter stands for the sampling frequency, which for this deployment is 1 Hz. Once the binning tool is initialized, you can use the bin_average function to average the data into ensembles.
[47]:
avg_tool = api.ADPBinner(n_bin=ds.fs * 300, fs=ds.fs)
ds_avg = avg_tool.bin_average(ds)
[48]:
ds_avg
[48]:
<xarray.Dataset> Size: 379kB
Dimensions: (time: 183, range: 28, dirIMU: 3, dir: 4, beam: 4,
earth: 3, inst: 3, q: 4, time_b5: 183, range_b5: 28)
Coordinates:
* time (time) datetime64[ns] 1kB 2020-08-15T00:22:30.001030683 ....
* dirIMU (dirIMU) <U10 120B 'streamwise' 'x-stream' 'vert'
* range (range) float64 224B 1.2 1.7 2.2 2.7 ... 13.2 13.7 14.2 14.7
* dir (dir) <U10 160B 'streamwise' 'x-stream' 'vert1' 'vert2'
* beam (beam) int32 16B 1 2 3 4
* earth (earth) <U1 12B 'E' 'N' 'U'
* inst (inst) <U1 12B 'X' 'Y' 'Z'
* q (q) <U1 16B 'w' 'x' 'y' 'z'
* time_b5 (time_b5) datetime64[ns] 1kB 2020-08-15T00:22:29.93849515...
* range_b5 (range_b5) float64 224B 1.2 1.7 2.2 2.7 ... 13.7 14.2 14.7
Data variables: (12/38)
c_sound (time) float32 732B 1.502e+03 1.502e+03 ... 1.498e+03
U_std (range, time) float32 20kB 0.04232 0.04293 ... nan nan
temp (time) float32 732B 14.49 14.59 14.54 ... 13.62 13.56 13.5
pressure (time) float32 732B 9.712 9.699 9.685 ... 9.58 9.584 9.591
mag (dirIMU, time) float32 2kB 3.534 3.565 ... -197.1 -197.1
accel (dirIMU, time) float32 2kB -1.261 -1.263 ... 9.714 9.712
... ...
boost_running (time) float32 732B 0.1267 0.1333 0.13 ... 0.2267 0.22 0.22
heading (time) float32 732B 3.287 3.261 3.337 ... 3.331 3.352 3.352
pitch (time) float32 732B -0.05523 -0.07217 ... -0.04288 -0.0429
roll (time) float32 732B -7.414 -7.424 -7.404 ... -6.433 -6.436
water_density (time) float32 732B 1.023e+03 1.023e+03 ... 1.023e+03
depth (time) float32 732B 10.28 10.26 10.25 ... 10.14 10.15 10.15
Attributes: (12/41)
fs: 1
n_bin: 300
n_fft: 300
description: Binned averages calculated from ensembles of s...
filehead_config: {"CLOCKSTR": {"TIME": "\"2020-08-13 13:56:21\"...
inst_model: Signature1000
... ...
has_imu: 1
beam_angle: 25
range_offset: 0.6
declination: 15.8
declination_in_orientmat: 1
principal_heading: 11.18984. Calculate Speed and Direction
Two additional variables that might be of interest, which are not automatically provided, are the magnitude of the horizontal velocity (referred to as U_mag or speed) and its direction (U_dir). These can be accessed via “shortcut” functions through the keyword velds, as demonstrated in the subsequent code block.
For a comprehensive list of these “shortcut” functions, you can refer to the DOLfYN documentation.
[49]:
ds_avg["U_mag"] = ds_avg.velds.U_mag
ds_avg["U_dir"] = ds_avg.velds.U_dir
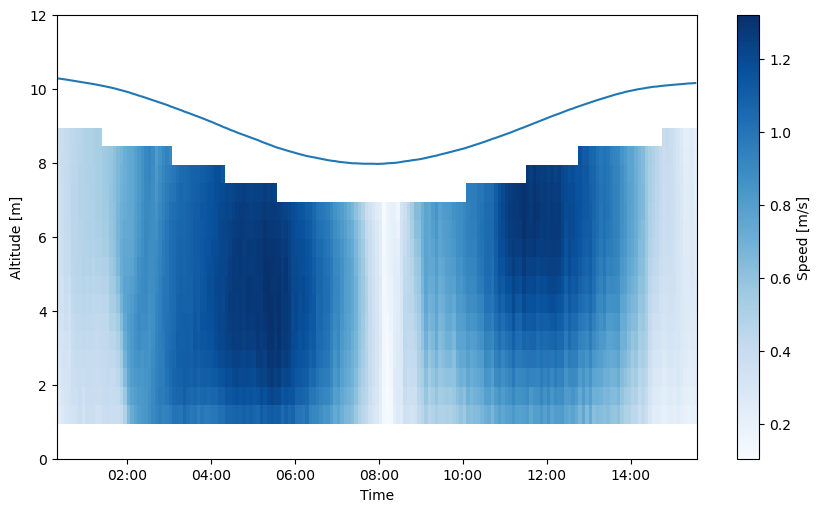
Plotting
Plotting can be accomplished through the user’s preferred package. Matplotlib is shown here for simplicity, and flow speed and direction are plotted below with a blue line delineating the water surface level.
[50]:
%matplotlib inline
from matplotlib import pyplot as plt
import matplotlib.dates as dt
ax = plt.figure(figsize=(10, 6)).add_axes([0.14, 0.14, 0.8, 0.74])
# Plot flow speed
t = dolfyn.time.dt642date(ds_avg["time"])
plt.pcolormesh(t, ds_avg["range"], ds_avg["U_mag"], cmap="Blues", shading="nearest")
# Plot the water surface
ax.plot(t, ds_avg["depth"])
# Set up time on x-axis
ax.set_xlabel("Time")
ax.xaxis.set_major_formatter(dt.DateFormatter("%H:%M"))
ax.set_ylabel("Altitude [m]")
ax.set_ylim([0, 12])
plt.colorbar(label="Speed [m/s]")
[50]:
<matplotlib.colorbar.Colorbar at 0x112d84c8410>
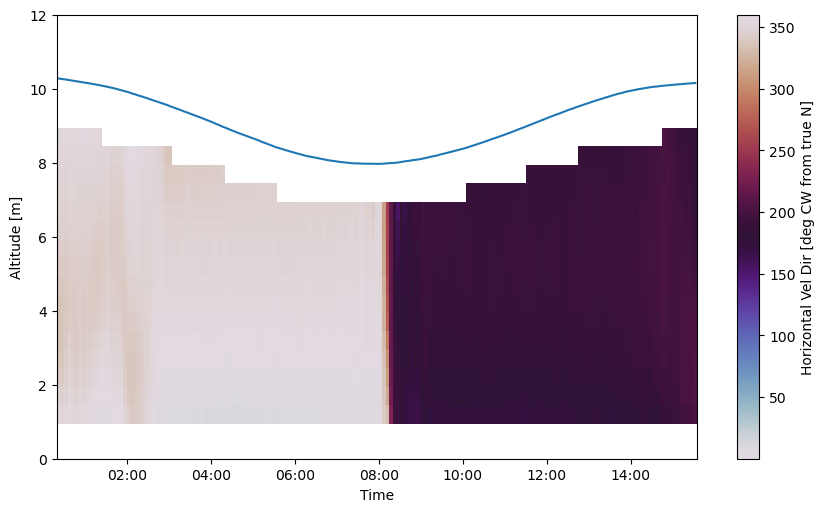
[51]:
ax = plt.figure(figsize=(10, 6)).add_axes([0.14, 0.14, 0.8, 0.74])
# Plot flow direction
plt.pcolormesh(t, ds_avg["range"], ds_avg["U_dir"], cmap="twilight", shading="nearest")
# Plot the water surface
ax.plot(t, ds_avg["depth"])
# set up time on x-axis
ax.set_xlabel("Time")
ax.xaxis.set_major_formatter(dt.DateFormatter("%H:%M"))
ax.set_ylabel("Altitude [m]")
ax.set_ylim([0, 12])
plt.colorbar(label="Horizontal Vel Dir [deg CW from true N]");
Saving and Loading DOLfYN datasets
Datasets can be saved and reloaded using the save and load functions. Xarray is saved natively in netCDF format, hence the “.nc” extension.
Note: DOLfYN datasets cannot be saved using xarray’s native ds.to_netcdf; however, DOLfYN datasets can be opened using xarray.open_dataset.
[52]:
# Uncomment these lines to save and load to your current working directory
# dolfyn.save(ds, 'your_data.nc')
# ds_saved = dolfyn.load('your_data.nc')
7. Turbulence Statistics
The next section of this jupyter notebook will run through the turbulence analysis of the data presented here. There was no intention of measuring turbulence in the deployment that collected this data, so results depicted here are not the highest quality. The quality of turbulence measurements from an ADCP depend heavily on the quality of the deployment setup and data collection, particularly instrument frequency, samping frequency and depth bin size.
Read more on proper ADCP setup for turbulence measurements in: Thomson, Jim, et al. “Measurements of turbulence at two tidal energy sites in Puget Sound, WA.” IEEE Journal of Oceanic Engineering 37.3 (2012): 363-374.
Most functions related to turbulence statistics in MHKiT-DOLfYN have the papers they originate from referenced in their docstrings.
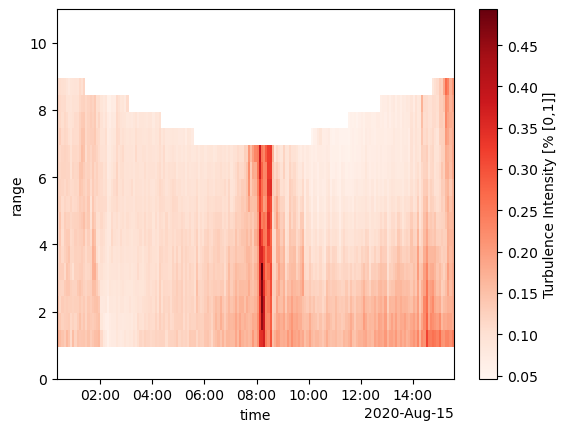
7.1 Turbulence Intensity
For most users, turbulence intensity (TI), the ratio of the ensemble standard deviation to ensemble flow speed given as a percent, is all most will need. In MHKiT, this can be simply calculated as <raw dataset>.velds.I, but be aware that this will be a conservative estimate. Another function, turbulence_intensity, is capable of subtracting instrument noise from this parameter and is discussed below. The noise-subtracted TI is more accurate and typically 1-2% lower than the
non-noise-subtracted estimation.
[53]:
# Turbulence Intensity
ds_avg["TI"] = ds_avg.velds.I
ds_avg["TI"].plot(cmap="Reds", ylim=(0, 11))
[53]:
<matplotlib.collections.QuadMesh at 0x112d5652650>
7.2 Power Spectral Densities (Auto-Spectra)
Other turbulence parameters include the TKE power- and cross-spectral densities (i.e the power spectra), turbulent kinetic energy (TKE, i.e. the variances of velocity vector components), Reynolds stress vector (i.e. the co-variances of velocity vector components), TKE dissipation rate, and TKE production rate. These quantities are primarily used to inform and verify hydrodynamic and coastal models, which take some or all of these quantities as input.
The TKE production rate is the rate at which kinetic energy (KE) transitions from a useful state (able to do “work” in the physics sense) to turbulent; TKE is the actual amount of turbulent KE in the water; and TKE dissipation rate is the rate at which turbulent KE is lost to non-motion forms of energy (heat, sound, etc) due to viscosity. The power spectra are used to depict and quantify this energy in the frequency domain, and creating them are the first step in turbulence analysis.
We’ll start by looking at the power spectra, specifically the auto-spectra from the vertical beam (“auto” meaning the variance of a single vector direction, e.g. \(\overline{u'^2}\), vs “cross”, meaning the covariance of two directions, e.g. \(\overline{u'w'}\)). This can be done using the power_spectral_density function from the ADPBinner we created (“avg_tool”). We’ll create spectra at the middle water column, at a depth of 5 m, and use a number of FFT’s equal to 1/3 the bin
size.
[54]:
rng = 5 # m
vel_up = ds["vel_b5"].sel(range_b5=rng, method="nearest") # vertical velocity
U = ds_avg["U_mag"].sel(
range=5, method="nearest"
) # flow speed, for plotting in the next block
ds_avg["auto_spectra_5m"] = avg_tool.power_spectral_density(
vel_up, freq_units="Hz", n_fft=ds_avg.n_bin // 2
)
In the auto-spectra, we’re primarly looking for three components: the energy-producing region, the isotropic turbulence region (so-called “red noise”), and the instrument noise floor (termed “white noise”).
The block below organizes and plots the power spectra by the corresponding ensemble speed, averaging them by 0.1 m/s velocity bins. Note that if an ensemble is missing data that wasn’t filled in, a power spectrum will not be calculated for that ensemble timestamp.
[55]:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
plt.rcParams.update({"font.size": 18, "font.family": "Times New Roman"})
def plot_spectra_by_color(auto_spectra, U_mag, ax, fig, cbar_max=4.0):
U = U_mag.values
U_max = U_mag.max().values
# Average spectra into 0.1 m/s velocity bins
speed_bins = np.arange(0.5, U_max, 0.1)
time = [t for t in auto_spectra.dims if "time" in t][0]
S_group = auto_spectra.assign_coords({time: U}).rename({time: "speed"})
group = S_group.groupby_bins("speed", speed_bins)
count = group.count().values
S = group.mean()
# define the colormap
cmap = plt.cm.turbo
# define the bins and normalize
bounds = np.arange(0.5, cbar_max, 0.1)
norm = mpl.colors.BoundaryNorm(bounds, cmap.N)
colors = cmap(norm(speed_bins))
# plot
for i in range(len(speed_bins) - 1):
ax.loglog(auto_spectra["freq"], S[i], c=colors[i])
ax.grid()
# create a second axes for the colorbar
cax = fig.add_axes([0.8, 0.07, 0.03, 0.88])
# cax, _ = mpl.colorbar.make_axes(fig.gca())
sm = mpl.colorbar.ColorbarBase(
cax,
cmap=cmap,
norm=norm,
spacing="proportional",
ticks=bounds,
boundaries=bounds,
format="%1.1f",
label="Velocity [m/s]",
)
# Add -5/3 slope line
m = -5 / 3
x = np.logspace(-1, 0.5)
y = 10 ** (-3) * x**m
ax.loglog(x, y, "--", c="black", label="$f^{-5/3}$")
ax.legend()
return ax, sm
# Set up figure
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
fig.subplots_adjust(left=0.2, right=0.75, top=0.95, bottom=0.1)
# Plot spectra by color
plot_spectra_by_color(ds_avg["auto_spectra_5m"], U, ax, fig, cbar_max=2.0)
# Set axes
ax.set(
xlabel="Frequency [Hz]",
ylabel="PSD [m2 s-2 Hz-1]",
xlim=(0.01, 1),
ylim=(0.0005, 0.1),
)
[55]:
[Text(0.5, 0, 'Frequency [Hz]'),
Text(0, 0.5, 'PSD [m2 s-2 Hz-1]'),
(0.01, 1),
(0.0005, 0.1)]
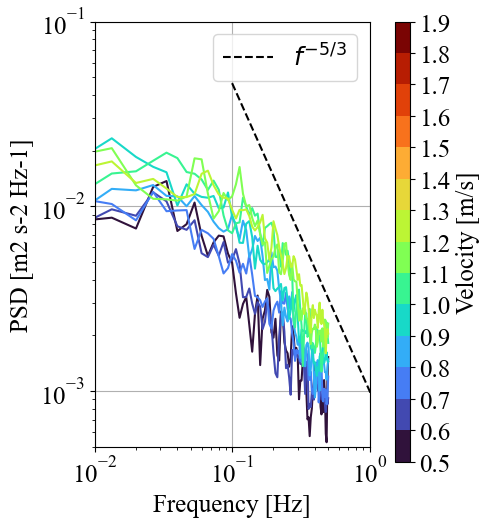
In the figure above, we can see the energy-producing turbulent structures below a frequency of 0.2 Hz (one tick to the right of “10^-1”). The isotropic turbulence cascade, seen by the dashed f^(-5/3) slope (from Kolmogorov’s theory of turbulence) begins at around 0.2 Hz and continues until we reach the Nyquist frequency at 0.5 Hz (1/2 the instrument’s sampling frequency, 1 Hz). The instrument’s noise floor can’t be seen here, but will show up as the flattened part of the spectra at the highest frequencies. For this instrument (Nortek Signature1000), the noise floor typically varies around 10^-3, depending on flow speed and range distance.
7.3 Instrument Noise
The next thing we want to do is calculate the instrument’s Doppler noise floor from the spectrum we calculated above. (We are making the assumption that the noise floor of the vertical beam is the same as the noise floor of the other 4 beams). This gives us a timeseries of the noise floor, which varies by instrument and with flow speed, at that depth bin.
We can do this using the doppler_noise_level function. The two inputs for this function are the power spectra and “pct_fN”, the percent of the Nyquist frequency that the noise floor exists. Because in this particularly dataset we can’t see the noise floor, we’ll just use 90% or pct_fN=0.9 as an example. If the noise floor began at 0.4 Hz and ran til our maximum frequency of 0.5 Hz, we’d use pct_fN = 0.4 Hz / 0.5 Hz = 0.8.
[56]:
ds_avg["noise_5m"] = avg_tool.doppler_noise_level(ds_avg["auto_spectra_5m"], pct_fN=0.9)
7.4 TKE Dissipation Rate
Because we can see the isotropic turbulence cascade (0.2 - 0.5 Hz) at this depth bin (5 m altitude), we can calculate the TKE dissipation rate at this location from the spectra itself. This can be done using dissipation_rate_LT83, whose inputs are the power spectra, the ensemble speed, the frequency range of the isotropic cascade, and the instrument’s noise.
[57]:
# Frequency range of isotropic turubulence cascade in same units as PSD frequency vector
f_rng = [0.1, 0.5]
# Dissipation rate
ds_avg["dissipation_rate_5m"] = avg_tool.dissipation_rate_LT83(
ds_avg["auto_spectra_5m"], U, freq_range=f_rng, noise=ds_avg['noise_5m']
)
We have just found the spectra and dissipation rate from a single depth bin at an altitude of 5 m from the seafloor, but typically we want the spectra and dissipation rates from the entire measurement profile. If we want to look at the spectra and dissipation rates from all depth bins, we can set up a “for” loop on the range coordinate and merge them together:
[58]:
import xarray as xr
spec = [None] * len(ds.range)
e = [None] * len(ds.range)
n = [None] * len(ds.range)
for r in range(len(ds["range"])):
# Calc spectra from each depth bin using the 5th beam
spec[r] = avg_tool.power_spectral_density(
ds["vel_b5"].isel(range_b5=r), freq_units="Hz"
)
# Calculate doppler noise from spectra from each depth bin
n[r] = avg_tool.doppler_noise_level(spec[r], pct_fN=0.9)
# Calc dissipation rate from each spectra
e[r] = avg_tool.dissipation_rate_LT83(
spec[r], ds_avg.velds.U_mag.isel(range=r), freq_range=f_rng, noise=n[r]
)
ds_avg["auto_spectra"] = xr.concat(spec, dim="range")
ds_avg["noise"] = xr.concat(n, dim="range")
ds_avg["dissipation_rate"] = xr.concat(e, dim="range")
del spec, n, e # save memory
Now that we have a profile timeseries of dissipation rate, we need apply some quality control (QC). Since we can’t look at each individual spectrum to ensure we can see the isotropic turbulence cascade, we want to QC the output from dissipation_rate_LT83 to make sure what was calculated actually falls on a f^(-5/3) slope. We can do this using the function check_turbulence_cascade_slope, which uses linear regression on the log-transformed LT83 equation (ref. to Lumley and Terray, 1983,
see docstring) to calculate the spectral slope for the given frequency range.
In our case, we’re calculating the slope of each spectrum between 0.2 and 0.5 Hz. We’ll use a cutoff of 20% for the error, but this can be lowered if there still appear to be erroneous estimations from visual inspection of the spectra.
[59]:
# Quality control dissipation rate estimation
slope = avg_tool.check_turbulence_cascade_slope(
ds_avg["auto_spectra"], freq_range=f_rng
)
# Check that percent difference from -5/3 is not greater than 20%
mask = abs((slope[0].values - (-5 / 3)) / (-5 / 3)) <= 0.20
# Keep good data
ds_avg["dissipation_rate"] = ds_avg["dissipation_rate"].where(mask)
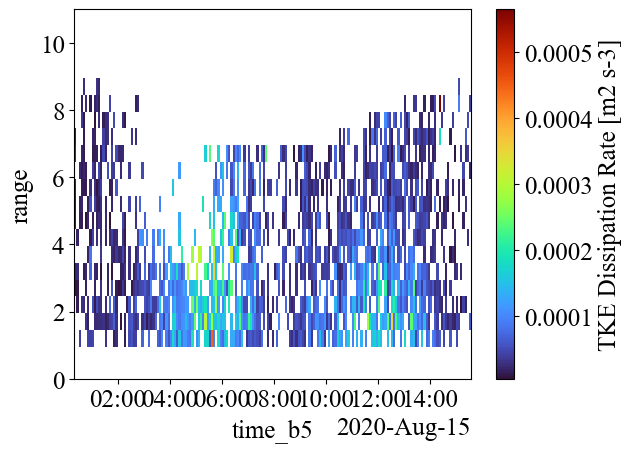
If we plot the dissipation rate below in a colormap, we can see that the profile map has a lot of missing data. One of the reasons is that the 1 Hz sampling rate doesn’t provide enough information needed to make dissipation rate estimations, and the other part is that turbulence measurements push the boundaries of what ADCPs are capable of.
Also, 1x10^-4 to 3x10^-4 \(m^2/s^3\) is reasonable for a dissipation rate estimate for the 1 - 1.5 m/s current speeds measured here. They can be a magnitude greater for faster flow speeds, typically increase closer to the seafloor, and depend heavily on bathymetry and regional hydrodynamics.
[60]:
ds_avg["dissipation_rate"].plot(cmap="turbo", ylim=(0, 11))
[60]:
<matplotlib.collections.QuadMesh at 0x112d7649190>
7.5 Noise-Corrected Turbulence Intensity
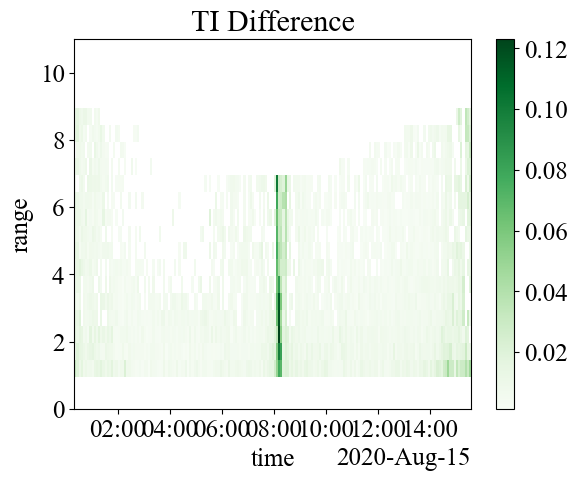
Now that we’ve calculated the noise floor for each ping, we can recalculate TI and include subtracting instrument noise using the turbulence_intensity function. If we subtract this from the non-noise corrected function, we can see there’s a large difference at slower slow speeds, but the average difference is about 0.008 (0.8%). Notice this will also remove measurements where noise is high.
[61]:
ds_avg["turbulence_intensity"] = avg_tool.turbulence_intensity(ds.velds.U_mag, noise=ds_avg["noise"])
(ds_avg["TI"] - ds_avg["turbulence_intensity"]).plot(cmap="Greens", ylim=(0, 11))
plt.title("TI Difference")
[61]:
Text(0.5, 1.0, 'TI Difference')
7.6 Reynolds Stress Components
The next parameters we’ll find here are the Reynolds normal and shear stresses (-\(\overline{u_iu_j}\)). Since we’re using the vertical beam on the ADCP, we can directly measure the vertical TKE component from the along-beam velocity using the turbulent_kinetic_energy function. This function is capable of calculating TKE for any along-beam velocity.
We can also use the so-called “beam-variance” equations to estimate the Reynolds stress tensor components (i.e. \(\overline{u'^2}\), \(\overline{v'^2}\), \(\overline{w'^2}\), \(\overline{u'v'}\), \(\overline{u'w'^2}\), \(\overline{v'w'^2}\)), which define the normal and shear stresses acting on an element of water. These equations are built into the functions stress_tensor_5beam and stress_tensor4beam.
Both of these functions will give comparable results, but stress_tensor_5beam takes into account instrument tilt, and stress_tensor_4beam does not. Both will throw a tilt warning if tilt is greater than 5 degrees.
Quick 5-beam ADCP lesson before we dive in:
There are a couple caveats to calculating Reynolds stress tensor components: 1. Because this instrument only has 5 beams, we can only find 5 of the 6 components (6 unknowns, 5 knowns) 2. Because the ADCP’s instrument (XYZ) axes weren’t aligned with the flow during deployment, we don’t know what direction these components are aligned to (i.e. the ‘u’ direction is not necessarily the streamwise direction) 3. It is possible to rotate the tensor, but we’d need to know all 6 components to do so properly (“coupled ADCPs”) 4. Measurements close to the seafloor can be suspect due to increased vertical flow. ADCPs operate under the “assumption of homogeneity”, which means that they can only accurate measure consistent horizontal currents with relatively little vertical motion.
As an example, we’ll calculate the Reynolds stresses from the stress_tensor_5beam function, which calculates the individual Reynolds stress tensor components and takes the same inputs: the raw dataset in “beam” coordinates, the instrument Doppler noise, the ADCP’s orientation and its beam angle. It outputs both the normal stress (“tke_vec”) and the shear stress (“stress_vec”) vector. Note, this function will drop at least one warning every time it’s run, primarily the coordinate system
warning. This function also requires the input raw data to be in beam coordinates, so we’ll create a copy of the raw data and rotate it to ‘beam’. If you do not, this function will do so automatically.
[62]:
dolfyn.rotate2(ds, "beam", inplace=True)
ds_avg["tke_vec"], ds_avg["stress_vec"] = avg_tool.stress_tensor_5beam(
ds, noise=ds_avg["noise"], orientation="up", beam_angle=25
)
c:\Users\mcve343\anaconda3\envs\work\Lib\site-packages\mhkit\dolfyn\adp\turbulence.py:407: UserWarning: The beam-variance algorithms assume the instrument's (XYZ) coordinate system is aligned with the principal flow directions.
warnings.warn(
There is one other important thing to note on Reynolds stress measurements by ADCPs: the minimum turbulence length scale that the ADCP is capable of measuring increases with range from the instrument. This means the instrument is only capable of measuring the stress transported by larger and larger turbulent structures as the beams travel farther and farther from the instrument head. One of the benefits of calculating w’w’ from the vertical beam is that it isn’t limited by this beam spread issue, though on its own it may not be particularly useful.
7.7 TKE Production
Though it can’t be found from this deployment, we’ll go over how to estimate the TKE shear production rate. Note that we’re assuming here that the buoyancy production is negligible and we’re in a well-mixed tidal channel. There isn’t a specific function in MHKiT-DOLfYN for production, but all the necessary variables are.
It is possible to estimate production rates from either an ADV or an ADCP aligned with the flow direction (so “X” would align with the principal flow direction). The following estimation for shear production rates takes into account both along- and cross-stream shear:
\(P = -\overline{u'w'}\frac{du}{dz} - \overline{v'w'}\frac{dv}{dz}\)
Note that the signs can get tricky but are important here. We found the Reynolds shear stresses -\(\overline{u'w'}\) and -\(\overline{v'w'}\) above using the Reynolds stress equations. If ADV data is available, those estimations are preferred because the ADV’s point measurement does not have the assumptions that ADCP measurements have.
The velocity shear components can be found from the aptly named functions dudz and dvdz in ADPBinner. These functions, which are useful alone in their own right, approximate the shear in the velocity vector between respective depth bins. There is always correlation between velocity measurements in adjacent depth bins, based on ADCP operation principles, which is why “approximate” is also used here for velocity shear.
The velocity shear functions operate on the raw velocity vector in the principal reference frame and need to be ensemble-averaged here. This can be done by nesting the d*dz function within the ADPBinner’s mean function. With the ensemble shear known, we can put all the components together to get a production estimation. If using ADV data, take the mean again of the “range” dimension.
[63]:
# Vertical shear gradients
upwp_ = ds_avg["stress_vec"][1]
vpwp_ = ds_avg["stress_vec"][2]
# Find shear velocity and and ensemble-average it
ds.velds.rotate2("principal", inplace=True)
dudz_raw = avg_tool.dudz(ds["vel"], orientation="up")
dudz = avg_tool.mean(dudz_raw.values)
dvdz_raw = avg_tool.dvdz(ds["vel"], orientation="up")
dvdz = avg_tool.mean(dvdz_raw.values)
# Calculate Production
P = -upwp_ * dudz - vpwp_ * dvdz
c:\Users\mcve343\anaconda3\envs\work\Lib\site-packages\mhkit\dolfyn\rotate\api.py:72: UserWarning: You are attempting to rotate into the 'principal' coordinate system, but the dataset is in the inst coordinate system. Be sure that 'principal_heading' is defined based on the earth coordinate system.
warnings.warn(
7.8 TKE Balance
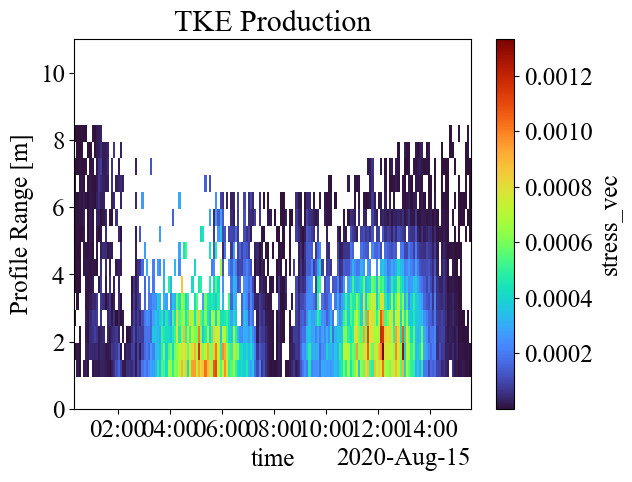
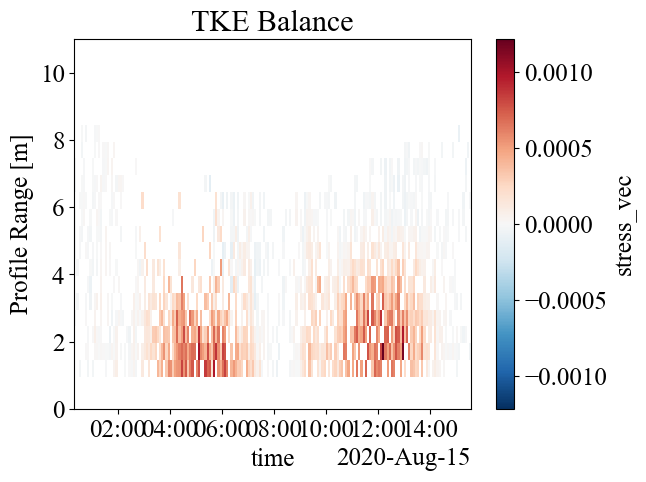
We can plot the production rates and the ratio of production rates to dissipation rates to get an understanding of the TKE balance.We always expect production to be greater than 0, though negative values can give us an indication of uncertainty. In a well mixed coastal environment, we expect production and dissipation to be approximately equal. Our production estimates are possibly high because our stress components aren’t aligned with the flow (1.3x10^-3 \(m^2/s^3\) is quite large), but if this weren’t the case, we would conclude that TKE is produced (kinetic energy is lost to turbulence) but not dissipated (turbulent energy is lost to entropy) here.
[64]:
# Remove estimations below 0
P = P.where(P > 0)
# Plot production rate
P.plot(cmap="turbo", ylim=(0, 11))
plt.title("TKE Production") # remove bogus title
# Plot difference between production and dissipation rate
plt.figure()
balance = P - ds_avg["dissipation_rate"].values
balance.plot(ylim=(0, 11))
plt.title("TKE Balance")
[64]:
Text(0.5, 1.0, 'TKE Balance')
[ ]: